Tôi học được gì khi tự viết một thư viện
--

Nếu bạn nào theo dõi các bài viết gần đây thì thấy tôi thường gọi các hàm từ một gói tên tabint. Các bạn sẽ lục tung google để tìm gói này nhưng sẽ không thấy vì đây là gói... do tôi tự viết và chưa đưa lên pip (nhưng nó đã có trên github :D).
Nếu bạn tò mò đọc thêm phần README thì sẽ thấy thực ra tôi cũng chẳng tự viết hết mọi thứ mà cũng vay mượn một số từ các thư viện nổi tiếng khác. Vậy tại sao tôi lại quyết định viết một gói riêng? Hay tôi đang rảnh rỗi thiết kế lại bánh xe? Hay tôi có ý đồ xấu gì khác?
Thực ra tôi không hề được lợi ích vật chất gì từ việc này. Đổi lại tôi học được rất nhiều điều khi viết tabint. Cá nhân tôi nghĩ rằng ai cũng nên thử viết một gói riêng cho mình. Đó giống như một công cụ trong quá trình làm việc của riêng mỗi cá nhân mà không có bất kì thư viện nào của người khác có thể thay thế được.
Hãy cũng đọc tiếp những gì tôi học được khi viết tabint, và biết đâu bạn cũng sẽ bị thuyết phục để làm điều tương tự. :D
Tôi viết lại những gì mình học được
Ở giai đoạn đầu, tôi chủ yếu triển khai những gì mình đã học được vào tabint.
Tôi học được rất nhiều về machine learning từ khóa machine learning của fastai vì vậy tabint có khá nhiều hàm biểu thị kết quả giống với khóa của fastai.

Tuy nhiên, không phải lúc nào tôi cũng copy code của người khác :p. Hàm thực hiện feature importance và phân chia data set được tôi tự viết sau khi đã hiểu về ý tưởng trong cách thực hiện.
Cá nhân tôi thấy rằng mình hiểu vấn đề rõ ràng hơn sau khi code xong một ý tưởng. Vì vậy tôi cố gắng code nhiều nhất có thể để cố gắng hiểu một vấn đề mới.
Tôi lười
Tôi là một người lười. Vì vậy tôi rất ngại khi phải viết một hàm lặp đi lặp lại mỗi lần gặp một bài toán mới. Chính vì lười nên tôi cố gắng viết tabint để tôi chỉ phải gõ code lần duy nhất, sau đó thì tôi chỉ cần gọi hàm và chạy.
Bạn sẽ thấy rõ điều này khi nhìn vào các hàm của tabint, ví dụ như dataset:

stratify = y ở hàm train_test_split sẽ giúp cho dữ liệu được phân chia đều theo phân phối của nhãn y. Đây là điều nên làm, vì vậy tôi để nó mặc định và sau này không cần quan tâm tới nó nữa.
Đôi khi trong quá trình phân tích, tôi muốn bỏ một biến khỏi mô hình. Tuy nhiên dữ liệu lúc này đã được chia thành 3 bộ train, valid, test set. Vì vậy tôi thường phải loại bỏ thủ công feature 3 lần. Vì lười (lại lười) tôi viết luôn một hàm để làm việc này thay vì lần nào cũng phải viết lại.

Cố gắng không lặp lại chính mình và không mất thời gian làm lại những cái cũ. Tôi nghĩ đó là cách tốt để có thời gian làm những cái mới hơn.
Tôi có trí nhớ kém
Vì vậy tôi cố gắng viết các class theo một cấu trúc chung, các biến cùng mục đích có cùng tên, vị trí các biến trong một hàm cũng được tôi cố gắng viết giống nhau giữa các hàm để mình không phải nhớ nhiều.
tabint có rất nhiều class về hình ảnh hóa. Các class này đều có classmethod để tính toán input cần thiết cho class. Các input bao gồm biến để đưa vào đồ thị và kết quả dạng bảng để tôi có thể nhìn thấy cả hình ảnh và số liệu cụ thể.
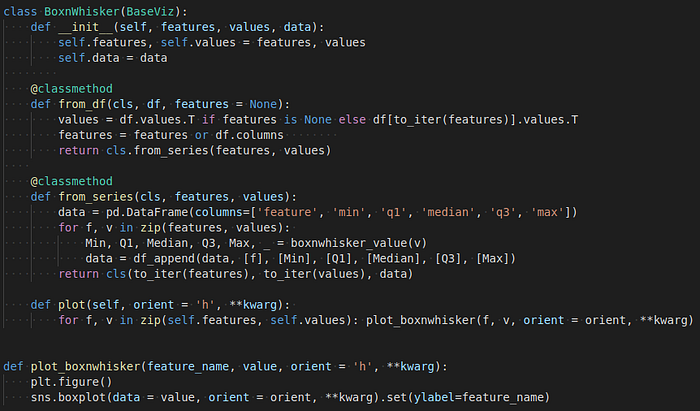
class BoxnWhisker chứa hàm plot để vẽ đồ thị, có biến data để lưu giá trị được biểu diễn bởi đồ thị, có 2 biến là features và values để vẽ đồ thị. Các hàm và biến này đúng với mọi class dùng để hình ảnh hóa trong gói tabint!
Khi bạn đã biết một class dùng cho một việc nên được viết theo cấu trúc như thế nào tức là bạn đã hiểu một phần những gì mình cần phải làm. Việc còn lại chỉ là triển khai các phần chi tiết theo khung đó. Bạn sẽ không cần phải lo lắng mình bỏ quên bước nào hay phần nào nữa.
Tôi tham lam
Tôi muốn các class phải đủ linh hoạt để dùng trong nhiều trường hợp, tuy nhiên cũng cần đủ tổng quát để không phải viết quá nhiều, nó cũng cần đủ gọn để tôi không phải nhớ quá nhiều.
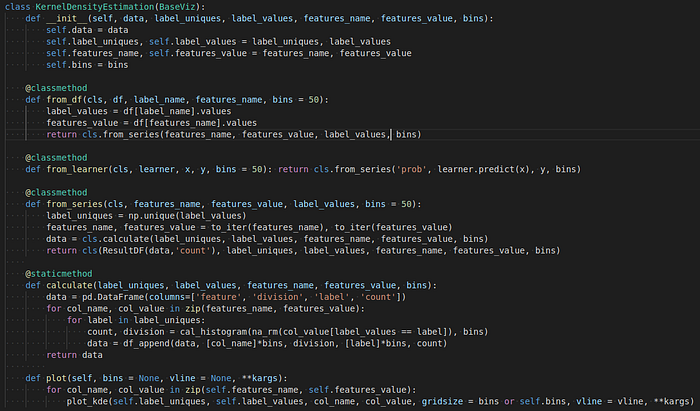
Class KernelDensityEstimation kế thừa các thuộc tính của class BaseViz. Nó cũng có nhiều classmethod để phục vụ cho từng loại input khác nhau. Tuy nhiên, dù input có từ dataframe hay từ learner thì nó cũng được quy về class method from_series. Ở đây, các bước tính toán là giống nhau với mọi input. Cá nhân tôi thấy cách viết như trên có thể thỏa mãn được một người tham lam như tôi. :D
Tôi thích cải tiến
Tôi thường có thói quen đọc lại code mình viết và tự hỏi sao hồi đó mình lại viết được như vậy hoặc tệ hơn là không hiểu mình đã viết gì :D. Tuy nhiên có một điều khác quan trọng hơn khi đọc lại code, đó là tôi biết nó ở đó, nó làm nhiệm vụ đó và tôi có thể cải tiến để nó tốt hơn.
Điều này rất khác với việc bạn google một đoạn code tốt nào đó trên stackoverflow để giải quyết một vấn đề trong một thời điểm, rồi sau đó lại quên nó đi. Việc giữ lại code trong một thư việc mà bạn hiểu rõ cấu trúc sẽ giúp bạn có khả năng cải tiến code và cũng là cải thiện khả năng giải quyết vấn đề của mình.
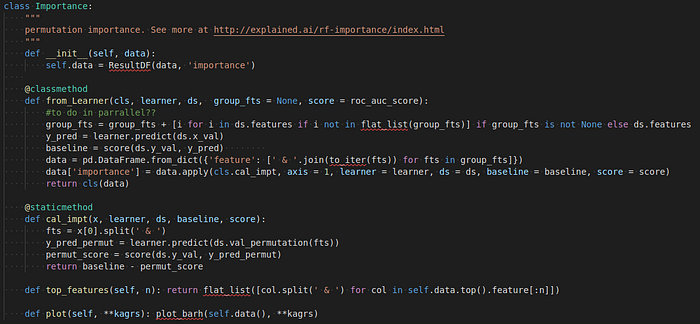
Bên trên là đoạn code xác định feature importance bằng phương pháp permutation importance. Tôi sử dụng hàm apply của pandas để đẩy nhanh quá trình tính toán. Tuy nhiên nó vẫn khá chậm và tôi đang nghĩ cách để tăng tốc độ của việc này. :D
Tôi thích tùy biến
Tôi là người thích tùy biến. Việc đầu tiên tôi thường làm khi cài phần mềm mới là tùy biến giao diện để nhìn vừa mắt hơn. Khi viết một gói riêng, tôi có thể lưu lại những tùy biến này và biến một số thư viện hoạt động theo ý riêng của mình.

Lưu ý rằng thư viện SHAP không hỗ trợ thay đổi màu trong tham số của các hàm. Tôi thay đổi bằng cách tác động vào biến colors của file plots.py của gói shap.
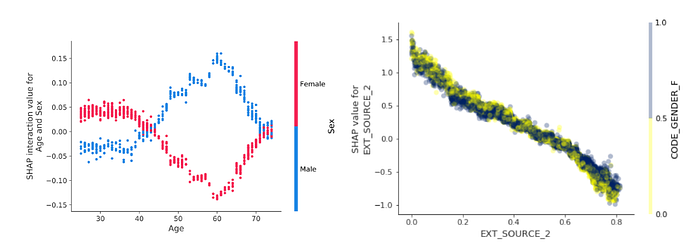
Các bạn có thể nói rằng màu ở bên phải xấu hơn. Tuy nhiên nó hữu dụng hơn nhiều so với màu đỏ-xanh khi các điểm bị chồng lấn. Việc để độ mờ nhỏ (alpha <1) cũng là một thủ thuật hữu ích khi vẽ đồ thị với các điểm chồng lấn lên nhau.
Hy vọng qua bài này bạn có thể thấy được điều gì đó thú vị từ một người có nhiều tật xấu như tôi :D. Chúc bạn có được nhiều niềm vui trong hành trình phân tích dữ liệu của mình :D.
